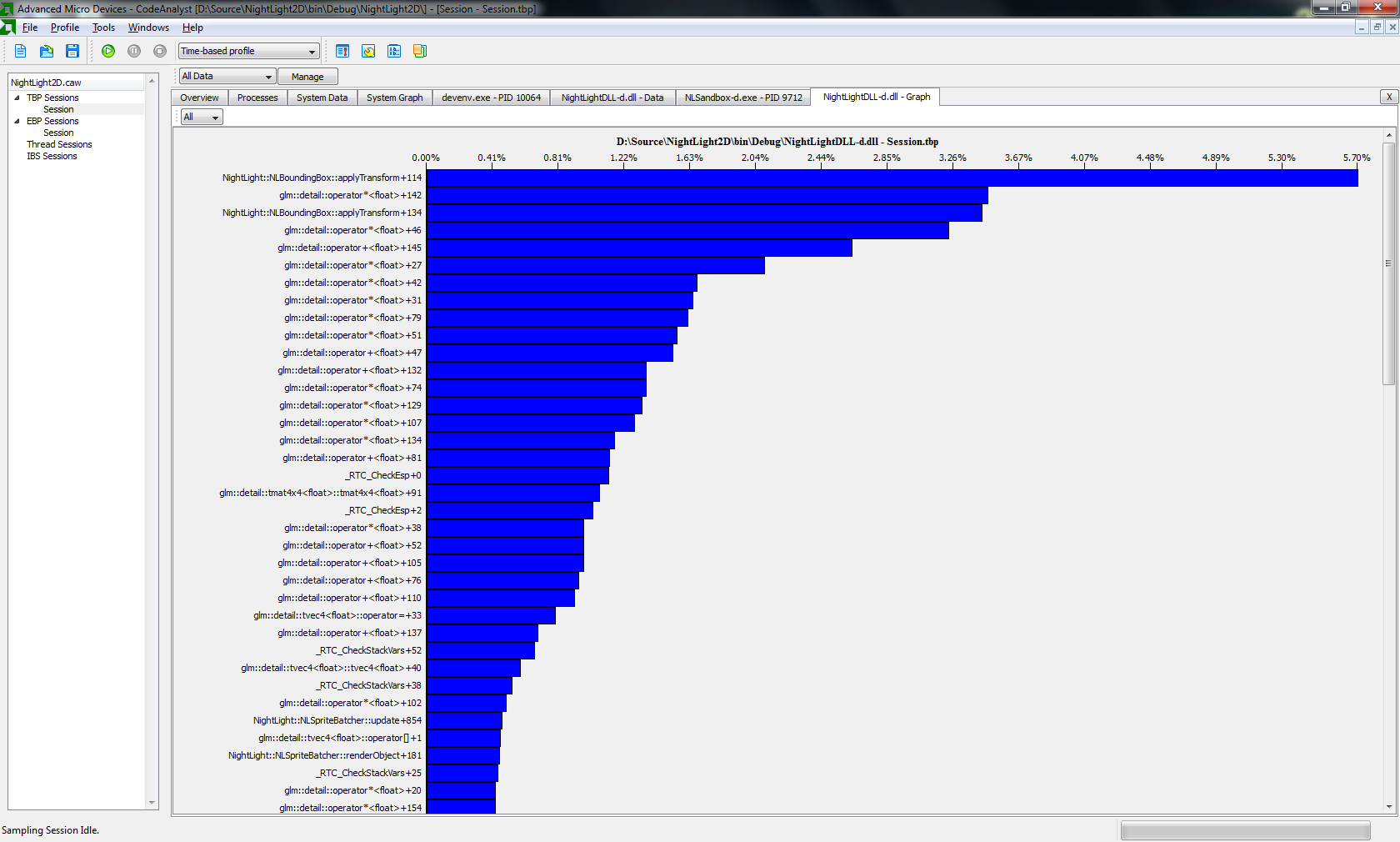
I am programming an OpenGL3 2D Engine. Currently, I am trying to solve a bottleneck. Please hence the following output of the AMD Profiler: http://h7.abload.de/img/profilerausa.png
{kind=link}
The data was made using several thousand sprites.
However, at 50.000 sprites the testapp is already unusable at 5 fps.
This shows, that my bottleneck is the transform function I use. That is the corresponding function: http://code.google.com/p/nightlight2d/source/browse/NightLightDLL/NLBoundingBox.cpp#130
void NLBoundingBox::applyTransform(NLVertexData* vertices)
{
if ( needsTransform() )
{
// Apply Matrix
for ( int i=0; i<6; i++ )
{
glm::vec4 transformed = m_rotation * m_translation * glm::vec4(vertices[i].x, vertices[i].y, 0, 1.0f);
vertices[i].x = transformed.x;
vertices[i].y = transformed.y;
}
m_translation = glm::mat4(1);
m_rotation = glm::mat4(1);
m_needsTransform = false;
}
}
I can't do that in the shader, because I am batching all sprites at once. That means, I have to use the CPU to calculate transforms.
My Question is: What is the best way to solve this bottleneck?
I don't use any threads atm, so when I use vsync, I get an extra performance hit too, because it waits for the screen to finish. That tells me I should use threading.
The other way to go would be to use OpenCL maybe? I want to avoid CUDA, because as far as I know it only runs on NVIDIA cards. Is that right?
post scriptum:
You can download a demo here, if you like:
http://www63.zippyshare.com/v/45025690/file.html
Please note, that this requires VC++2008 installed, because it is a debug version for running a profiler.